RAG vs Agentic RAG: When to Use Which in HazelJS
A practical comparison of standard RAG and Agentic RAG in HazelJS. Learn what problems each solves, when to choose which, and how to get started with backlinks to npm and docs.
Author: HazelJS Team
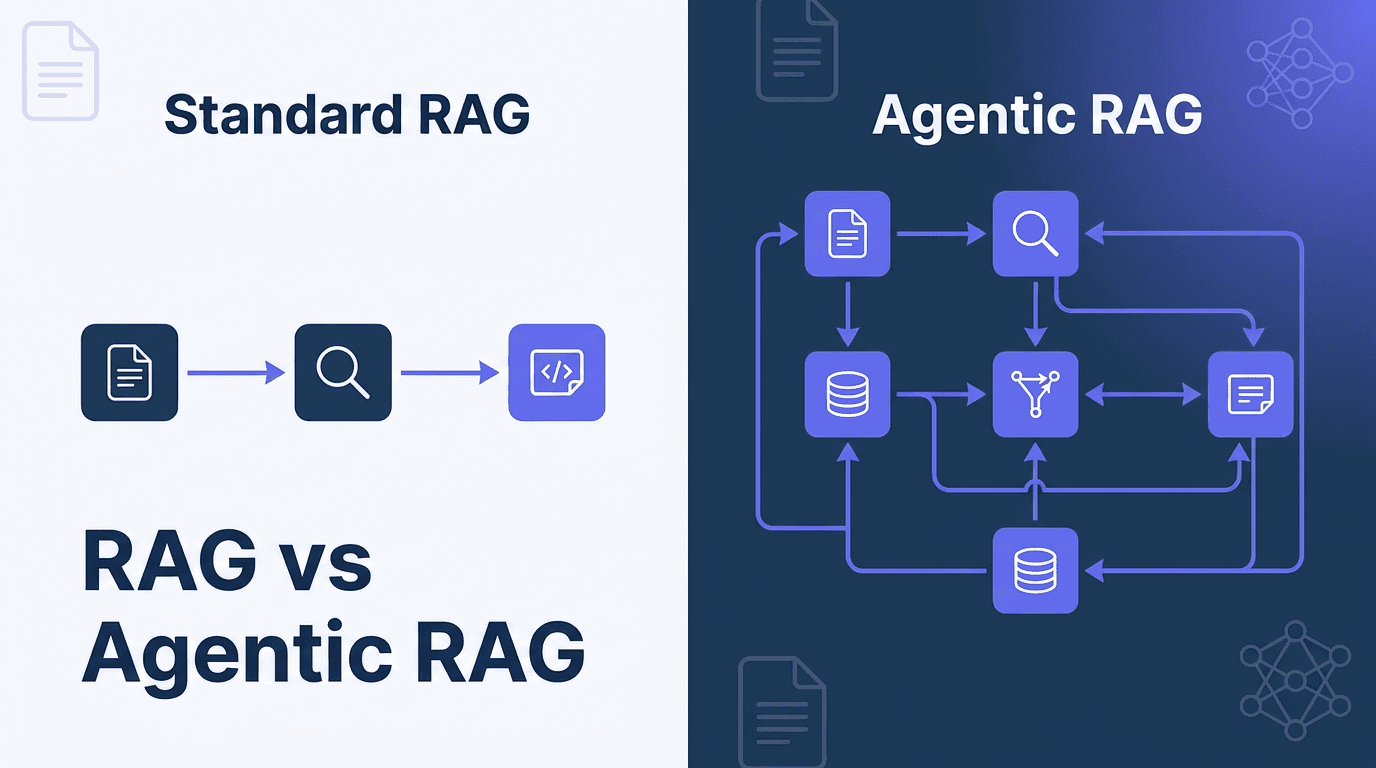
Both RAG and Agentic RAG in HazelJS use the same foundation — vector stores, embeddings, and document retrieval. The difference is how they handle queries and improve over time. Standard RAG is a fixed pipeline; Agentic RAG adds autonomous, adaptive behavior on top. Here's a practical comparison and when to choose each.
Packages & Links
- @hazeljs/rag — RAG and vector search (npm · docs)
- @hazeljs/ai — LLM integration for RAG (npm · docs)
- @hazeljs/agent — Agent runtime with RAG integration (npm · docs)
- @hazeljs/memory — Shared memory for RAG and agents (npm · docs)
What RAG (Standard) Solves
Standard RAG in @hazeljs/rag focuses on core retrieval and generation:
| Problem | Solution |
|---|---|
| LLM hallucination / outdated knowledge | Retrieves relevant documents from a vector store and augments the LLM prompt with them |
| Document ingestion | 11 document loaders (PDF, Markdown, web, GitHub, etc.) and text splitters for chunking |
| Semantic search | Vector similarity search over embeddings (Pinecone, Qdrant, Weaviate, ChromaDB, Memory) |
| Basic retrieval strategies | Similarity, MMR (diversity), hybrid (vector + keyword) |
| Context-aware Q&A | RAGPipelineWithMemory for conversation history and entity memory |
| Knowledge graph retrieval | GraphRAG for entity/relationship and thematic search across documents |
| Answer generation | Retrieve → build context → generate answer via LLM |
Typical use cases: FAQ bots, simple Q&A over docs, help centers, product catalogs.
What Agentic RAG Solves (Beyond Standard RAG)
Agentic RAG adds autonomous, adaptive capabilities on top of the same retrieval primitives:
| Problem | Solution |
|---|---|
| Complex multi-part questions | @QueryPlanner — Decomposes into sub-queries and runs them (optionally in parallel) |
| Low retrieval quality | @SelfReflective — Evaluates results and iteratively improves (up to N iterations) |
| Choosing the right retrieval strategy | @AdaptiveRetrieval — Picks similarity, hybrid, or MMR based on query/context |
| Abstract or vague queries | @HyDE — Generates hypothetical answers and uses them to improve retrieval |
| Bad or irrelevant results | @CorrectiveRAG — Detects low relevance and can fall back (e.g. web search) |
| Multi-step reasoning across docs | @MultiHop — Chains multiple retrieval steps (e.g. breadth-first) |
| Conversational context | @ContextAware — Uses conversation window, entity tracking, topic modeling |
| Query phrasing | @QueryRewriter — Expansion, synonyms, clarification for better coverage |
| Trust and citations | @SourceVerification — Checks freshness, authority, requires citations |
| Improvement over time | @ActiveLearning + @Feedback — Learns from user feedback, adapts ranking |
| Performance | @Cached — LRU cache with TTL for repeated queries |
Typical use cases: Research assistants, legal/medical Q&A, customer support with context, knowledge management that improves with use.
Side-by-Side Comparison
| Dimension | RAG | Agentic RAG |
|---|---|---|
| Query handling | Single query → single retrieval | Plans, rewrites, decomposes, adapts |
| Quality | Fixed pipeline | Self-reflection, correction, verification |
| Strategy | You choose (similarity, hybrid, MMR) | Chooses strategy per query |
| Reasoning | One retrieval step | Multi-hop across documents |
| Learning | Static | Learns from feedback |
| Complexity | Simpler, predictable | More capable, more moving parts |
Decision Guide
Use standard RAG when:
- You have straightforward Q&A or document search
- Queries are simple and well-formed
- You want predictable latency and cost
- You don't need multi-step reasoning or self-correction
Use Agentic RAG when:
- Questions are complex or multi-part
- You need better handling of vague or abstract queries
- Multi-hop reasoning across documents is required
- You want self-correction and quality verification
- The system should improve from user feedback over time
Detailed Example: Standard RAG
A complete Standard RAG setup — document loading, chunking, indexing, and full retrieve-then-generate flow:
import {
RAGPipeline,
OpenAIEmbeddings,
MemoryVectorStore,
DirectoryLoader,
RecursiveTextSplitter,
RetrievalStrategy,
} from '@hazeljs/rag';
import OpenAI from 'openai';
// 1. Setup embeddings and vector store
const embeddings = new OpenAIEmbeddings({
apiKey: process.env.OPENAI_API_KEY,
model: 'text-embedding-3-small',
dimensions: 1536,
});
const vectorStore = new MemoryVectorStore(embeddings);
await vectorStore.initialize();
// 2. Configure text splitting for optimal chunk size
const splitter = new RecursiveTextSplitter({
chunkSize: 800,
chunkOverlap: 150,
separators: ['\n\n', '\n', '. ', ' '],
});
// 3. Create pipeline with LLM for answer generation
const openai = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
const llmFunction = async (prompt: string) => {
const res = await openai.chat.completions.create({
model: 'gpt-4o-mini',
messages: [{ role: 'user', content: prompt }],
});
return res.choices[0].message.content ?? '';
};
const pipeline = new RAGPipeline(
{
vectorStore,
embeddingProvider: embeddings,
textSplitter: splitter,
topK: 5,
},
llmFunction
);
await pipeline.initialize();
// 4. Load documents from disk (or inline)
const docs = await new DirectoryLoader({
dirPath: './knowledge-base',
recursive: true,
extensions: ['.md', '.txt'],
}).load();
// 5. Index — pipeline handles chunking automatically
const ids = await pipeline.addDocuments(docs);
console.log(`Indexed ${ids.length} chunks`);
// 6. Query: single retrieval + optional LLM answer
const response = await pipeline.query('What is HazelJS?', {
topK: 5,
strategy: RetrievalStrategy.HYBRID, // or SIMILARITY, MMR
llmPrompt: 'Answer based on context: {context}\n\nQuestion: {query}',
includeContext: true,
});
console.log('Answer:', response.answer);
console.log('Sources:', response.sources.length);
response.sources.forEach((s, i) => {
console.log(` [${i + 1}] ${s.content.slice(0, 80)}... (score: ${s.score})`);
});
Key points: One query → one retrieval → one answer. You choose the strategy (similarity, hybrid, MMR) upfront. Predictable latency and cost.
Detailed Example: Agentic RAG
A complete Agentic RAG setup with custom decorators for different retrieval scenarios:
import {
AgenticRAGService,
QueryPlanner,
SelfReflective,
AdaptiveRetrieval,
HyDE,
CorrectiveRAG,
ContextAware,
QueryRewriter,
SourceVerification,
ActiveLearning,
Feedback,
Cached,
MemoryVectorStore,
OpenAIEmbeddings,
Document,
} from '@hazeljs/rag';
// Custom class with decorators for different use cases
class ResearchAssistant {
constructor(private vectorStore: MemoryVectorStore) {}
// Basic retrieval: query planning + self-reflection + adaptive strategy + cache
@QueryPlanner({ decompose: true, maxSubQueries: 5, parallel: true })
@SelfReflective({ maxIterations: 3, qualityThreshold: 0.8 })
@AdaptiveRetrieval({ autoSelect: true, contextAware: true })
@Cached({ ttl: 3600 })
async retrieve(query: string) {
return this.vectorStore.search(query, { topK: 5 });
}
// HyDE + Corrective RAG for abstract or vague queries
@HyDE({ generateHypothesis: true, numHypotheses: 3 })
@CorrectiveRAG({ relevanceThreshold: 0.7, fallbackToWeb: true })
@Cached({ ttl: 1800 })
async hydeRetrieve(query: string) {
return this.vectorStore.search(query, { topK: 5 });
}
// Context-aware for multi-turn conversations
@ContextAware({ windowSize: 5, entityTracking: true, topicModeling: true })
@QueryRewriter({ techniques: ['expansion', 'synonym'], llmBased: true })
@Cached({ ttl: 600 })
async conversationalRetrieve(query: string, sessionId: string) {
return this.vectorStore.search(query, { topK: 5, sessionId });
}
// Verified retrieval with citations (legal, medical)
@SourceVerification({
checkFreshness: true,
verifyAuthority: true,
requireCitations: true,
})
@SelfReflective({ maxIterations: 2, qualityThreshold: 0.85 })
async verifiedRetrieve(query: string) {
return this.vectorStore.search(query, { topK: 5 });
}
// Learning from feedback
@ActiveLearning({ feedbackEnabled: true, retrainThreshold: 100 })
@Feedback()
async provideFeedback(resultId: string, rating: number, relevant: boolean) {
// Stored by decorator for ranking improvement
}
}
// Usage
const embeddings = new OpenAIEmbeddings({ apiKey: process.env.OPENAI_API_KEY });
const vectorStore = new MemoryVectorStore(embeddings);
await vectorStore.initialize();
const documents: Document[] = [
{
content: 'HazelJS is a TypeScript framework for AI-native backends. It includes RAG, agents, and memory.',
metadata: { source: 'docs', category: 'framework' },
},
{
content: 'Agentic RAG adds query planning, self-reflection, and adaptive retrieval via decorators.',
metadata: { source: 'docs', category: 'rag' },
},
// ... more documents
];
await vectorStore.addDocuments(documents);
const assistant = new ResearchAssistant(vectorStore);
// Simple query — uses retrieve() with all agentic features
const results1 = await assistant.retrieve('What is HazelJS?');
// Abstract query — HyDE generates hypothetical answers first for better matching
const results2 = await assistant.hydeRetrieve(
'How do modern frameworks handle AI and retrieval together?'
);
// Conversational — "it" refers to "HazelJS" from previous turn
const sessionId = 'user-123';
await assistant.conversationalRetrieve('What is HazelJS?', sessionId);
const results3 = await assistant.conversationalRetrieve(
'How does it handle RAG?', // uses context: "it" = HazelJS
sessionId
);
// Verified with citations — for compliance-sensitive use cases
const results4 = await assistant.verifiedRetrieve(
'What RAG strategies does HazelJS support?'
);
// Provide feedback — system learns over time
await assistant.provideFeedback(results4[0].id, 5, true);
Key points: Different methods for different scenarios. Decorators compose — add @HyDE for abstract queries, @ContextAware for chat, @SourceVerification for citations. System improves from feedback.
Real-World Scenario: Same Query, Different Approaches
Query: "What vector stores does HazelJS support and how do I switch between them?"
Standard RAG: Single semantic search. If the answer is spread across multiple docs or uses different phrasing, you might get partial results. You'd typically increase topK or try hybrid search manually.
const response = await pipeline.query(query, {
topK: 10,
strategy: RetrievalStrategy.HYBRID,
});
// One retrieval pass. Hope the chunks contain both "vector stores" and "switch"
Agentic RAG: Query planner decomposes into sub-queries: "vector stores HazelJS", "switch vector store", "configure different vector store". Runs them in parallel, merges and deduplicates. Self-reflection checks if results answer the full question; if not, retries with refined queries.
const results = await assistant.retrieve(query);
// Internally: 3 sub-queries → parallel search → merge → reflect → improve if needed
Query: "Compare machine learning, deep learning, and reinforcement learning for NLP tasks"
Standard RAG: One query. You might get a chunk that mentions all three, or you might get three separate chunks. No guarantee they're comparable or that the "best for NLP" part is covered.
Agentic RAG: @QueryPlanner breaks it into: "machine learning NLP", "deep learning NLP", "reinforcement learning NLP", "compare ML approaches". @MultiHop can chain: find ML definition → find NLP applications → find comparison. @SelfReflective evaluates whether the combined results actually answer "compare" and "best for NLP" — if not, it refines and retries.
Quick Start (Minimal)
Standard RAG
import { RAGPipeline, OpenAIEmbeddings, MemoryVectorStore } from '@hazeljs/rag';
const embeddings = new OpenAIEmbeddings({ apiKey: process.env.OPENAI_API_KEY });
const vectorStore = new MemoryVectorStore(embeddings);
const rag = new RAGPipeline({
vectorStore,
embeddingProvider: embeddings,
topK: 5,
});
await rag.initialize();
await rag.addDocuments(documents);
const results = await rag.query('What is HazelJS?');
Agentic RAG
import { AgenticRAGService } from '@hazeljs/rag/agentic';
import { MemoryVectorStore } from '@hazeljs/rag';
import { OpenAIEmbeddings } from '@hazeljs/ai';
const vectorStore = new MemoryVectorStore(new OpenAIEmbeddings());
const agenticRAG = new AgenticRAGService({ vectorStore });
const results = await agenticRAG.retrieve('Compare machine learning approaches for NLP');
Learn More
- RAG Package — Vector stores, loaders, GraphRAG, and core pipeline
- RAG vs Agentic RAG Guide — Full comparison and decision guide
- RAG Patterns — Advanced patterns and best practices
- Agentic RAG Guide — Full Agentic RAG feature reference
- Memory System — Context-aware AI with RAG integration
Install
npm install @hazeljs/rag @hazeljs/ai
For Agentic RAG, the agentic decorators are part of @hazeljs/rag — import from @hazeljs/rag/agentic.
Try it and share your feedback: GitHub · npm · hazeljs.com